31 Jul, 2015
Post by Sean Harnedy
Introducing the Four Vs of RFID Data Collection
Data is the heart of every RFID application. For all of the RFID-enabled systems running in the enterprise, the Enterprise Operations Manager must deal with the RFID data that is collected, stored, analyzed, and integrated into the overall enterprise business.
The lifecycle of the collected RFID data for first generation RFID applications typically involved collection, temporary storage, analysis, and then deletion. With the evolution of technologies now available to store vast amounts of data on inexpensive data storage, data is now seen as a valuable asset and something that should be stored for further analysis and data mining. New fields such as predictive analytics allow for companies to derive value from the huge amounts of data they are will now store.
Big data is one of the hottest topics in enterprise operations today. There is an oft repeated maxim that “data is the new oil”. Big data deals with the four “Vs”: volume, velocity, variety, and veracity. Data now demands cost-effective and innovative forms of data processing for enhanced insights and decision making.
The real benefit of big data is the potential insights an Operations Manager can derive from this new, large, and expanding resource. If big data including the collected RFID data is the next big thing, then companies need to prepare new business models that exploit this.
For example, RFID asset collection and inventory management systems currently read tags, create reports, and then most likely discard the data. With new big data technologies the data is now saved for more in-depth data mining and analytics. The enterprise supply chain can now be analyzed more deeply and information can be shared across the enterprise for a more complete view of trends and for the ability to predict future directions.
Big Data implementations are predominantly done using Apache Hadoop. It is an open-source software framework written in Java for distributed storage and distributed processing of very large data sets on computer clusters built with commodity hardware. In Hadoop all the modules are designed with the basic assumption that node hardware failures are commonplace and thus should be automatically handled in software by the framework.
The core of Apache Hadoop consists of a storage part (Hadoop Distributed File System (HDFS)) and a processing part (MapReduce). Hadoop splits the data files into large fixed-sized blocks and distributes them amongst the nodes in the cluster so that MapReduce can process the blocks in parallel and create the results for output.
Hadoop has a large and ever growing ecosystem for all of the additional supporting tasks that are required to process the data. These include tasks for data ingestion, scheduling, coordination, machine learning, benchmarking, security, and other applications.
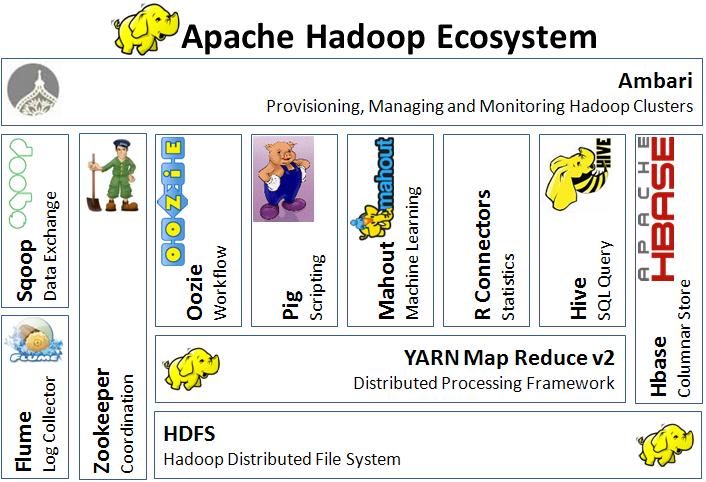
The Hadoop Ecosystem
Does your enterprise currently collect ever growing large amounts of RFID data? Have you considered the possible value of your big data? Are you considering technologies such as Hadoop to process and analyze this information?
Going forward new applications will be developed to make use of the big data that will contain the RFID tag collections. These apps will more and more deal with the volume, velocity, variety, and veracity of this data that will need to work with your RFID components. The RFID and Big Data ecosystems will need to work seamlessly together to provide effective and efficient solutions for your enterprise data.
For additional information on RFID components including readers, printers, and accessories contact us at the Gateway RFID store.